gzipの圧縮レベルと速度の関係を調べてみた

gzipってやつには圧縮レベルなんてオプションがありますが、あれと速度の関係はどんな感じなんでしょうね? 気になったので調べてみました。
テストに使ったのはpython付属のgzipライブラリ。tmpfs上でテストしたので読み書きのオーバーヘッドはかなり小さいはず。 データにはwikipediaのgzipの記事を100回繰り替えしたものを使ってみました。5.5MBくらい。 コードは末尾に。
そんなことより結果から。
| 圧縮レベル | 圧縮[秒] | 伸長[秒] | 圧縮後のサイズ | 圧縮率 |
|---|---|---|---|---|
| オリジナル | 0 | 0 | 5,457,300 | 1 |
| 1 | 0.0565 | 0.0233 | 1,704,911 | 0.312 |
| 2 | 0.0610 | 0.0232 | 1,637,668 | 0.300 |
| 3 | 0.0684 | 0.0225 | 1,599,015 | 0.293 |
| 4 | 0.0821 | 0.0223 | 1,485,118 | 0.272 |
| 5 | 0.1087 | 0.0222 | 1,444,208 | 0.264 |
| 6 | 0.1392 | 0.0220 | 1,426,554 | 0.261 |
| 7 | 0.1515 | 0.0215 | 1,422,199 | 0.260 |
| 8 | 0.1758 | 0.0214 | 1,418,481 | 0.259 |
| 9 | 0.1772 | 0.0215 | 1,418,481 | 0.259 |
レベルが上がると圧縮の時間が伸びるけれど、伸長は変わらない。
グラフ化するとこんな感じ。
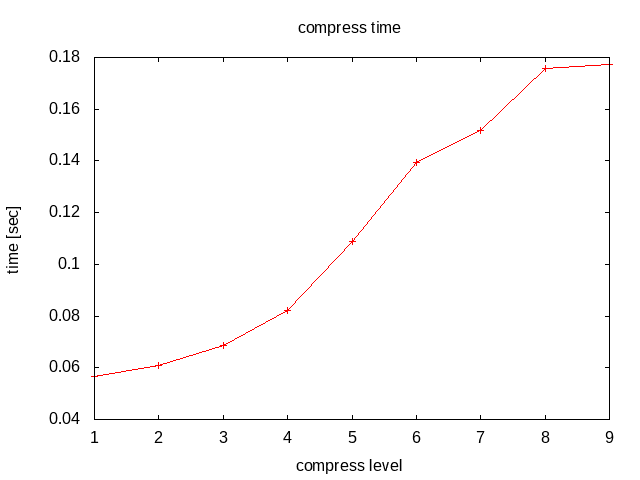
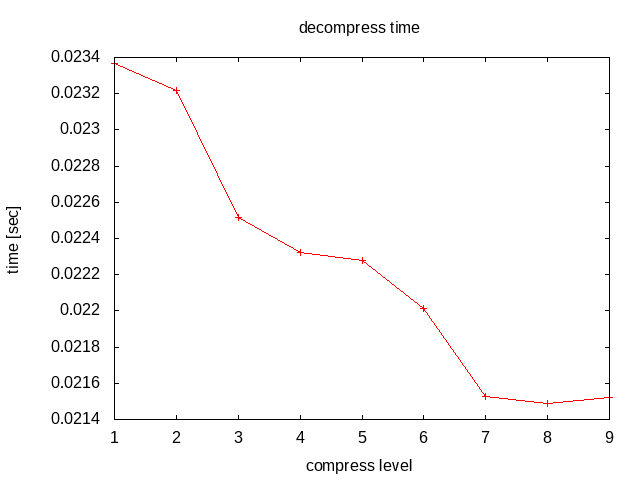
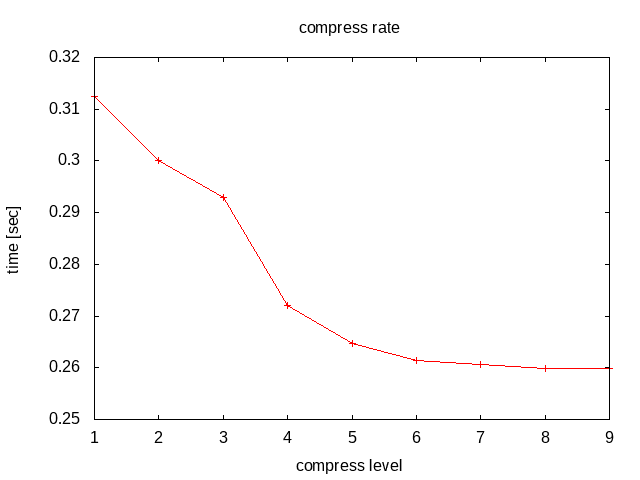
上から順に圧縮にかかる時間、伸長にかかる時間、圧縮率。
圧縮レベル6を越えたあたりから時間がかかるばっかで圧縮率が変わらない。不毛な感じ。 レベルが上がるにつれて伸長にかかる時間が若干減ってるのは・・・何だろう? IO関連か?
こうやってみると、大抵デフォルトに設定されてるレベル6ってのは実にバランス取れてるんだなぁと思ったり。
テスト用に使ったコードはこんな感じ。
import gzip import timeit import urllib.request TRY = 100 DATA = urllib.request.urlopen('http://ja.wikipedia.org/wiki/Gzip').read() * 100 def comp(level): with gzip.open('test.gz', 'wb', compresslevel=level) as fp: fp.write(DATA) def decomp(): with gzip.open('test.gz', 'rb') as fp: fp.read() if __name__ == '__main__': print('level\tcomp\tdecomp\tsize') print('original\t0\t0\t{0}'.format(len(DATA))) for i in range(1, 10): co = timeit.timeit(lambda : comp(i), number=TRY)/TRY size = len(open('test.gz', 'rb').read()) de = timeit.timeit(decomp, number=TRY)/TRY print('{0}\t{1}\t{2}\t{3}'.format(i, co, de, size))
同じ圧縮レベルをまとめて試すのは本当はよくないんだろうけれど、まあ面倒くさいので。